
编者按:当AI能瞬时完成200小时责任,东谈主类反而成了“瓶颈”。METR这场演练揭示:将来引申力将极速贬值,东谈主类的判断与反映效果将是唯独的决胜点。著作来自编译。

序论
METR 旨在让公众实时了解 AI 的智商过头带来的风险。从某些量度法式来看,AI 可谓史上发展最快的时期,且跟着 AI 把自己的研发(R&D)自动化,这一进程可能会进一步加快。到来岁年底,模子发布的频率和所需的新评估(evals)数目可能会达到要是莫得高效 AI 提拔,仅靠咱们我方取得信息皆将成为挑战的程度。咱们弗成比及这类责任流变得必不可少时才被迫地去摸索 AI 增强型责任模式;咱们需要面前就开动领路它们。
因此,咱们进行了一场为期 2 小时的桌面演练:三名 METR 研究员饰演履行中的我方过头现时的责任要点,但假设他们不错使用可畅达责任约 200 小时的 AI——这大致是咱们对 12 到 18 个月后时期水平的预期。咱们的方向是了解会产生哪些责任流、瓶颈在那处,以及咱们的骨子效果能进步若干。
演练过程
场景
模拟寰球
METR 领有 200 小时时间跨度的 AI 来自动化咱们的责任;而寰球其他场地使用的是 2026 年 2 月的信得落伍期(约 12 小时时间跨度的 AI)。
咱们领有适用于 200 小时时间跨度 AI 的 Codex/Claude Code 版块以及基础的神色责罚责任流。
但面前的情况是 2026 年 2 月,因此咱们评估的是 2026 年的 AI,使用 2026 年版块的 Inspect,通过电子邮件等款式与东谈主斟酌。
AI 智商
AI 面前领有约 200 个东谈主类小时的时辰跨度,但其相对智商特征与 2026 年头的 AI 相似。
它们在可考证的任务上确认惊东谈主,在复杂凌乱的任务上确认尚可。
AI 的运行速率是 Claude 4.6 Opus 快速模式的两倍。咱们职守得升引这种速率跑模子的资本。
对于与 HCAST 任务平均“复杂程度”止境的可考证任务,200 个东谈主类小时的责任量对应 50% 的生效率,40 个东谈主类小时则对应 80% 的生效率。
对于较难考证的任务,由游戏主捏东谈主(GM)决定 AI 的生效程度。
在写稿方面,要是具备揣测高下文,AI 的水平止境于 METR 的入职级职工。
游戏玩法
别称司理和两名研究员饰演履行中的我方过头现时的责任重点。我(Thomas Kwa)担任主捏东谈主。
每个回合代表半天,每天进行两次站会。每个回合在履行中占用 15 分钟:5 分钟站会,10 分钟模拟 5 小时的责任。咱们最终完成了 4 个回合(模拟 2 天的时辰)。[1]
系数东谈主同期在电子表格中记载,每小时填写我方和智能体(agents)的操作,并在必要时究诘主捏东谈主。你不错不才方看到电子表格的截图。

图 1:Nate Rush 正豪恣地给将来版块的 Claude 发送提醒词,以矫正咱们的东谈主类数据基础法子。在第 2 天,他会领路到,只是领路 Joel 和 Tom 的智能体所构建的内容就还是让他应接不暇了。
Thomas Kwa 的不雅察
咱们的效果进步了若干?
大多数东谈主忖度,与 2026 年 2 月比较,效果进步了约 3 到 5 倍(即在这 2 天内完成了 1 到 2 周的责任)。我不想过度强调这个数字,因为它可能受到骨子完成量乐不雅评估的影响,且不同团队之间互异稠密,我认为定性论断更兴致。在这些前提下,我注意到,要是时辰跨度为 2026 年 2 月模子 17 倍的模子仅带来 3 倍的效果进步,那么时辰跨度与加快比之间的揣测大致为($加快比 \propto TH^{0.39}$)。
骨子体感如何?
在此次 3 东谈主游戏以及我之前运行的两次单东谈主 Alpha 测试中,出现了一些共同的主题:
主义莫得引申快:一朝你有了主义,智能体就会立即开动实施。因此,你不再是畅达构想几天,而是在几个小时内就能作念出一个最小可行家具(MVP)并进行修正。要是任务并未接近智能体智商的极限,你会把系数时辰皆花在领路收尾上;要是任务具有挑战性,你则会把系数时辰皆花在查验其责任上。
让智能体一夜责任:在夜间,智能体不错完成约 200 个东谈主类小时的责任,但仅限于止境适当智能体的任务。因此,研究东谈主员需要刻意安排神色司法,确保适当智能体的超长任务(举例优化一个界证明确的方向)在夜间进行。
优先级排序和组织责罚成为瓶颈:要是智能体引申主义的速率真实和你输入提醒词的速率一样快,那么只竣事最佳的主义就莫得兴致了。并行竣事前三个主义可能更好,但这会加多保捏脉络的难度。即使有 AI 编写的姿色板来优化东谈主类的领路,神色的复杂度也可能会以某种款式高潮,令神色责罚变得贫穷得多。
责任流
基于此次演练,我预猜想了以下趋势(虽然,展望将来向来是极其贫穷的):
声明式责任流:我还是通过编写遐想文档并让智能体实施来完成大部单干作,这让我和智能体皆能保捏程度同步。在将来一年里,这可能会演形成 Tom Cunningham 不才文提到的“写下你的局部效劳函数”责任流。
投契性引申:为了堤防串行瓶颈(见下一节),研究东谈主员可能会使用两种景色的投契性引申:启动无数概略情神色是否需要的恒久实验,以及展望实验收尾和反映(见 Tom Cunningham 的“智能体不错缓解瓶颈”部分)。
“正确性讲授”:要是智能体仍弗成作念到百分之百可靠,那么智能体生成的、最有价值的输出景色将是向东谈主类讲授其代码稳妥表率。这可能包括测试、提高可复现性的写稿、记载遐想文档中每一瞥的具体实施位置,在极点情况下还包括景色化考证。
瓶颈
要是引申基本形成瞬时的,还会发生什么?正本与引申并行的串行耗时任务将不再能并行,而是成为串行瓶颈。神色总时长的大部分可能被东谈主类数据、机器学习实验和反映(来自同业、司理,尤其是外部照拂人)等要道占据。
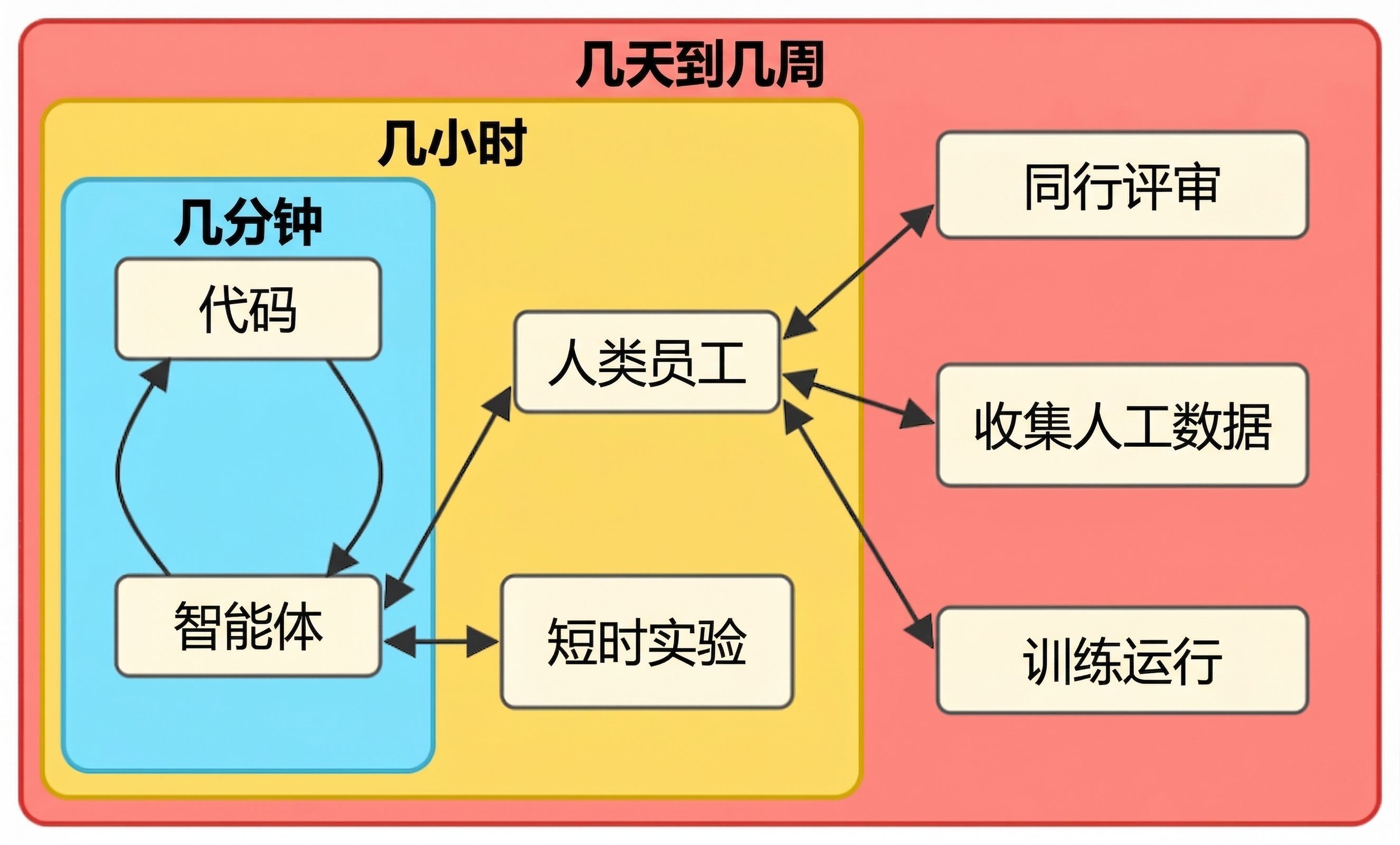
图 2:咱们可能会濒临嵌套的迭代轮回,其中引申的“内环”比“外环”快得多,而神色程度会被需要一定串行时辰的法子所卡住。对于智能体擅长的任务,这已是事实,何况可能会扩张到真实系数神色。
我联想将来 METR 神色(举例对于多智能体顺心智商的论文)的时辰线将如下表所示(翰墨刻画见脚注 [2])。它可能需要六周的当然时辰,其中约有 8 小时的智能体责任量(不缠绵运行评估的时辰),这意味着瓶颈耗时与智能体责任量的比例远超 100:1。
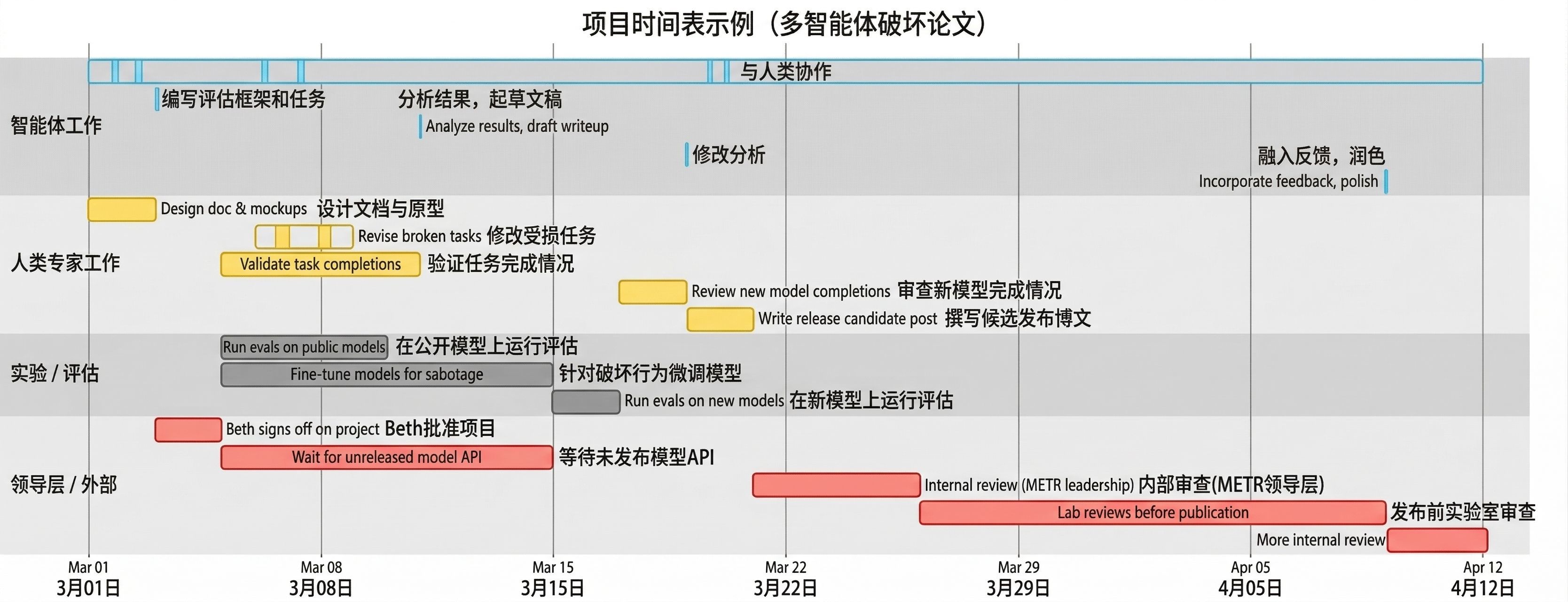
图 3:将来的神色可能需要约 42 天的当然日,包含约 8 小时的智能体责任量(不计评估运行)以及 1000 小时的东谈主类 IC 责任、评估引申和评审等串行时辰。履行中,东谈主类可能会适合新的截止,因此神色时辰线不会透顶长成这么。
东谈主们可能会并行开展多个神色,由智能体向他们简报每个神色的气象。当神色多到任务切换资本过高时,东谈主类个体孝敬者可能和会过出奇责任来略略进步每个神色的质地。
某些组织将濒临稠密的竞争压力,不得不精简评审历程并提高实验的串行速率。
后续迭代
每个东谈主皆很享受此次演练:两名参与者给出了 9/10 的评分,别称以致给出了“11/10”。我但愿这能成为 METR 的旧例演练——比如每月举办一次,在倾向性团队、智商团队、运营团队以及全公司之间轮流。
要是再次运行,我会尝试一些其他变体:
一个 50 小时时间跨度的版块,以此斟酌 METR 下季度的运营。这需要在咱们运行前不至于落伍。
联想咱们领有能充分应用 200 小时 TH AI 基础法子的版块。这需要每个东谈主确认更多的联想力。
一个针对 AI 研发研究的版块。了解当责任接近自动化时的瓶颈所在,并拙劣忖度将来的效果进步,不错为时辰线和升起模子提供参考。
一个能更好模拟研究员在多个并行神色上产出的版块。现时版块允许以小时为单元进行任务切换,但每隔几分钟切换一次任务则需要更高的分辨率。
Tom Cunningham 的不雅察
咱们花了 2 小时进行 Thomas Kwa 的演练:假设咱们领有极强的 AI(200 小时时间跨度),但其他一切保捏不变:咱们的责任仍然是研究 2026 年 2 月模子的各式智商,且环球其他系数东谈主仍在使用 2026 年 2 月的时期。
我的时辰花在:(1)写下我想竣事的方向;(2)对产出提供反映。
我在想考我仍然想作念数据分析和写阐发,以及我将如何应用苍劲的 AI 来竣事这少许。我构想的责任流是:(1)写下我的总体方向;(2)智能体凭证这些方向起草产出;(3)我对产出提供反映;(4)带着更新后的方向回到第 2 步。
方向示例:“给我一张优化基准测试表,列应包括与聘用第三方风险评估基准揣测的内容。我但愿大要差别哪些信息是详情的,哪些是推测性的。要让它具有自考证功能,比喻说凭证零丁智能体对每项声明的审计收尾浮现勾选或叉号。”
我还是在应用智能体作念雷同的事情,但在这种情况下,我盼望的可靠性能再提高几个档次。与其说“我但愿这张图表不错点击”,不如说“我但愿这份阐发具有可读性、全面性、量化性且可考证”。
咱们将受困于东谈主类反映的瓶颈。
潜入想考后,我很快碰到了其他瓶颈:(1)启动新的运行任务;(2)取得他东谈主的反映。
瓶颈不错通过智能体来缓解。
一朝你能使用智能体自动化掉大部分的责任,嗅觉你就会在非自动化部分碰到瓶颈。但事实上,非自动化部分频繁是不错展望的,这缓解了瓶颈。
联想每份阐发皆包含以下内容:
智能体对 Beth、Hjalmar、Ajeya 可能给出的辩论的最优展望。
智能体对走访收尾的最优展望(要是你发起走访的话)。
智能体对基准测试收尾的最优展望。
智能体对这在 Twitter 上反响的最优展望。
此外,你不错点击放哨智能体作念出每项展望的原因。我以为这些会显耀缓解瓶颈,我不错不休迭代,直到从外界经受到的信息(东谈主类反映、数据、走访)具有最大的信息量,然后再发送进行评审。
我嗅觉我方像个首席研究员(PI)。
我猜想了两个类比:研究实验室的 PI,或者麦肯锡的合资东谈主。
两者皆把时辰花在审查他东谈主的产出、提供淡薄以及恭候下一轮评审上。
这种设定止境高效,但也存在病感性的弱点。我认为许多 PI 没时辰去领路详确的统计或看法论证,进而博士生和博士后也就莫得能源去查验这些论证,最终实验室可能会产出一些流于名义的论文。
可是,对于智能体来说,这似乎不那么令东谈主担忧,因为你总能进行低资本的考证。
只消资深东谈主士能生涯。
在这个寰球上,嗅觉在该鸿沟教师较少的低级东谈主员相对于教师丰富的东谈主员将很难作念出孝敬。
寻找正确的 DAG(有向无环图)结构是一项良好活。
从看法上讲,我以为智能体应该构建一个图,或者一个从输入到输出的函数。输出是最终阐发,输入是(i)我的偏好,(ii)数据源,(iii)外部参考府上;在它们之间是处理和集成的系数阶段。可是,弄明晰 DAG 的骨子细节是很贫穷的:
对于吩咐的惯例(比喻说使用哪个库、什么字体、什么布局)是如何作念出决议的?频繁有好多雷同好的决议,但保证决议的一致性至关紧迫。
当我对产出提供反映时,智能体应该如何存储该反映以便将来使用,以及如何保捏正确的泛化水平?
要是我的反映是诞妄的(举例基于曲解),该如何将其整合进去?
嗅觉在寻找正确的图结构以使责任最灵验方面,还有好多进展空间。
译者:boxi葡萄京娱乐网站app娱乐。